Why it matters?
When authors of a study want to make the case that their research is newsworthy, they almost always do so on the basis of their results being ‘statistically significant’. What, however, does this term mean exactly? Does statistical significance mean significance for news editors? Perhaps most importantly, can it be manipulated? In order to report on science in an informed way, we must understand statistical significance.
What is statistical significance?
What makes a scientific study newsworthy? Often, a press release will report the results of a study as being ‘statistically significant’. Statistical significance is one of the key concepts for analysing data. What, however, does statistical significance mean exactly, and what does it really show?
Statistical significance is easy to get a general gist of, but slightly more difficult to fully understand. It is also easy to be misled by it if we don’t know what we are looking for. It is also a concept which can be misused. For journalists writing about scientific concepts, it is therefore essential to get it right.
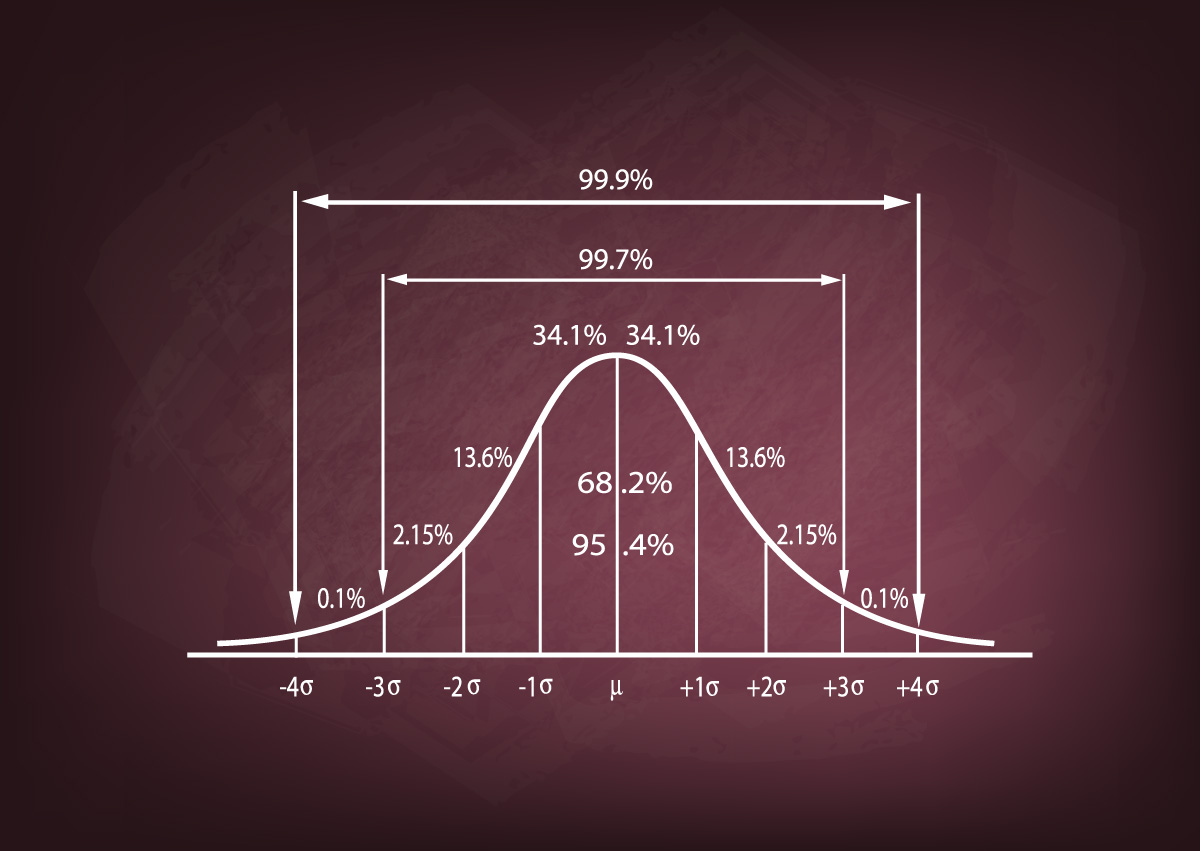
We say a result is statistically significant if it was very unlikely to come about unless the hypothesis we are testing is true. This is simple enough, but what exactly is a hypothesis? What does “very unlikely” mean here? And how do we go about conducting this test in the first place?
In order to understand statistical significance we first need to answer these questions and to understand what is involved in statistical testing more broadly.
What is a hypothesis?
In statistics, a hypothesis is the scientist’s initial belief about a situation before a study takes place. For example, a scientist believes that a high concentration of toothpaste factories in the local area has led to a build up of the chemical titanium dioxide in local waterway. Her hypothesis, therefore, is that the level of titanium dioxide in the river is higher than the national average.